基于轻量级php搜索sphider站内搜索安装说明
- 时间:
- 浏览:1566
- 来源:无双科技
安装
1. 解压缩文件,然后将它们复制到服务器,例如,复制到
/ home / youruser / public_html / sphider (后称为[path_of_sphider]) 。
2. 在服务器中,在MySQL中创建一个数据库来保存Sphider数据。
a)在命令提示符下键入(登录MySQL):
mysql -u <您的用户名> -p 出现提示时输入密码。
b)在MySQL中,键入:
CREATE DATABASE sphider;
当然,您可以为数据库使用其他名称代替 sphider 。
c)使用 exit 退出MySQL。
有关如何创建数据库以及授予/获取必要权限的更多信息,请访问 MySQL.com。
3. 在 设置 目录中,编辑 database.php 文件,然后更改 $ database , $ mysql_user , $ mysql_password 和 $ mysql_host 以更正值(如果您不知道 $ mysql_host 应该是 什么 ,它应该保持原样 -'localhost ') 。
4. 在浏览器中 打开 install.php 脚本( 管理 目录),这将创建Sphider操作所需的表或者可以使用Sphider发行版的sql目录中给出的tables.sql脚本手动创建表。 在提示符下,键入 mysql -u <您的用户名> -p sphider_db <[sphider的路径] /sql/tables.sql
5. 在 admin 目录中,编辑 auth.php 以更改管理员用户名和密码(默认值为'admin'和'admin')。
6. 在浏览器中 打开 admin / admin.php 并开始建立索引。
7. search.php 是默认的搜索页面。
索引选项
完整 :继续进行索引编制,直到没有其他可允许的链接为止。
到深度 :索引到给定的深度,其中深度表示从起始页面可以离开页面的“点击”次数。 深度0意味着只有起始页面被索引,深度为1个索引页开始,所有从它等链接到的网页
重新建立索引 :选中此复选框,索引是即使网页已经被收录被迫。
蜘蛛可以离开网域 :默认情况下,Sphider永远不会离开给定的域,因此不会遵循domain.com指向domain2.com的链接。 通过选中此选项,Sphider可以离开域,但是在这种情况下,强烈建议定义适当的必须包含/必须不包含字符串列表,以防止蜘蛛走得太远。
必须包含/不得包含 :请参阅 此处 以获得说明。
客制化
如果要更改Sphider的默认行为,则可以通过管理界面或直接 在 settings 目录中 编辑 conf.php 来执行此操作 。 要更改搜索页面的外观以适合您的网站,请在 模板 目录中 修改或添加 模板 。 修改 search.css 文件以及页眉和页脚模板( header.html 和 footer.html ) 应该足够了 。 通过编辑其余模板文件,可以进行较大的修改。 admin / ext.txt 中提供了未检查索引的文件类型列表 。 未索引的常用单词列表在
include / common.txt 。
从命令行使用索引器
可以使用以下语法从命令行蜘蛛化网页:
php spider.php <options>
其中<options>是
-所有重新索引数据库中的所有内容
-u 将网址设置为索引
-F将索引深度设置为全(无限深度)
-d 将索引深度设置为
-l允许蜘蛛离开初始域
-r设置Spider重新索引网站
-m <字符串>设置网址必须包含的字符串(使用\ n作为多个字符串之间的分隔符)
-n <字符串>设置网址不得包含的字符串(使用\ n作为多个字符串之间的分隔符)
例如,要对http:/ / www.domain.com/test.html进行爬网并将其索引到深度2,请使用
php spider.php -u http:/ /ww w.domain.com/test.html -d 2
如果需要要重新索引相同的URL,请使用
php spider.php -u http:/ /ww w.domain.c_om/test.html -r
索引pdf和doc文件
可以通过外部二进制文件为PDF和doc文件建立索引。 下载并安装 pdftotext 和 catdoc 并在conf.php中设置location(path)(请注意,在Windows下,您不应在定义可执行文件的路径时使用空格)。 另外,在“管理”部分中,选中“索引pdf”和“索引doc”框(或者,在conf.php中将$ index_pdf和$ index_doc参数设置为1)。
防止页面被索引
Robots.txt
防止页面被索引的最常见方法是使用robots.txt标准,方法是将robots.txt文件放入服务器的根目录中,或在页面标题中添加必要的meta标签(有关如何为此,请参见 此处 )。
必须包含/不得包含字符串列表
Sphider支持的功能强大的选项是定义站点的必须包含/不包含字符串列表(为此,请在“索引”屏幕中单击“高级”选项)。 在“必须不包括”列表中包含字符串的所有url都将被忽略。 同样,将忽略“必须包含”列表中不包含任何字符串的任何url。 字符串列表中的所有字符串都应以换行符(输入)分隔。 例如,为防止将您站点中的论坛编入索引,可以将ww w.yoursite.com/forum添加到“不得包含”列表中。 这意味着所有包含该字符串的url将被忽略,并且不会被索引。 还支持使用Perl样式正则表达式而不是文字字符串。 每个以'*'开头的字符串都被视为正则表达式,因此'* / [a] + /'
忽略链接
<a href..>标记中的Sphider尊重rel =“ nofollow”属性,因此,例如<a href="foo.html" rel="nofollow>中的链接foo.html被忽略。
忽略页面的一部分
Sphider包含一个选项,可将部分页面排除在索引之外。 例如,当某些关键字出现在大多数页面的某些部分(例如页眉,页脚或菜单)时,这可以用于防止搜索结果泛滥。 <!-sphider_noindex->??和<!-/ sphider_noindex->??标记之间的页面的任何部分均未编入索引,但是会跟随其中的链接。
Dome下载地址:
https://www.wsjianzhan.com/morenfenlei/phpsphidersousuozhanneisousuo.html
猜你喜欢
Navicat 15 激活码终结无法使用解决方案及激活教程
最新版的NavicatPremium15已经发布了是一款数据库管理工具,是一个可多重连线资料库的管理工具,它可以让你以单一程式同时连线到MySQL、SQLite、Oracle及
2023-10-20

宝塔Apache环境设置url路径不区分字母大小写
Linux服务器的大小写敏感有时候很不方便,在地址栏里一定要输入准确的URL才能访问,对搜索引擎和用户不是很友好,那么如何解决LINUX服务器URL的大小写问题今天同步碰到一个
2022-10-12
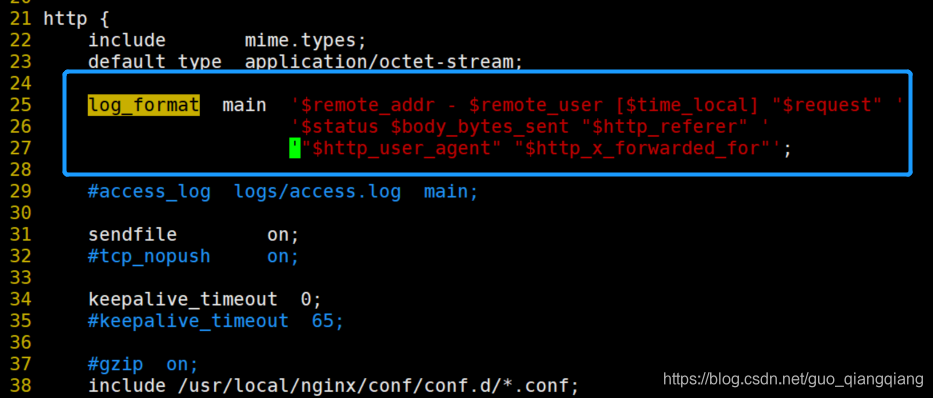
Nginx配置规则错误:unknown log format "main"
网站配置由apche换成nginx系统后,重启时出现错误提示Nginx配置规则错误:nginx:[emerg]unknownlogformat"main"in/www/serv
2022-10-12
thinkphp上线后 /captcha 验证码无法加载显示
ThinkPHP的验证码在本地就OK的显示正常,一上线就不显示也没有报500错,GD库安装正常线上错误显示结果为:找到你的验证码的控制器具体文件路径(下面是我的)vendor/
2021-09-28
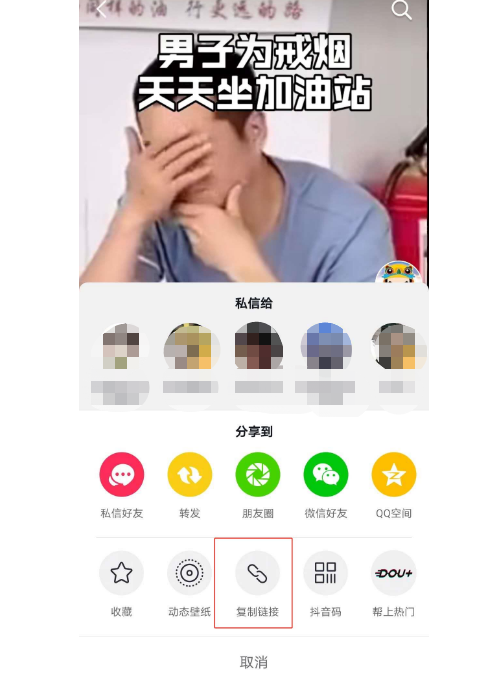
怎样把抖音视频链接发到网站上去
抖音现在很火,很多朋友都知道手机能够看抖音视频和上传视频,但是如何把抖音视频加入到网站上来,接下来一起来看看吧:我们在抖音APP里,打开某一条视频,点击右侧下方的分享小图标,然
2021-09-19
